R code to accompany Real-World Machine Learning (Chapter 5): Event Modeling
TweetAbstract
The rwml-R Github repo is updated with R code for the event modeling examples from Chapter 5 of the book “Real-World Machine Learning” by Henrik Brink, Joseph W. Richards, and Mark Fetherolf. Examples given include reading large data files with the fread function from data.table, optimization of model parameters with caret, computing and plotting ROC curves with ggplot2, engineering date-time features, and determining the relative importance of features with the varImp function in caret.
Event-Modeling Data
The data for the event modeling examples in chapter 5 of the book is from the Kaggle Event Recommendation Engine Challenge. The rules of the challenge prohibit redristribution of the data, so the reader must download the data from Kaggle.
Using fread
In order to work through the examples, features from the rather large
event.csv file are processed several times. To save time, an alternative to
the read.csv function is needed. This is where the fread function from the
data.table library comes in. It is similar to read.table but
faster and more convenient. On my MacBook Pro, it took only seven seconds to read
the event_id, lat, and lng features from the >1GB events.csv data file.
events <- fread(file.path(dataDir, "events.csv"),
sep=",",
colClasses = c("integer64",
rep("NULL",6),
"numeric",
"numeric",
rep("NULL",101)))Initial cross-validated ROC curve and AUC metric
Once a training data set is built with features from the events.csv,
train.csv, and users.csv files, the caret train function is used
to train a random forsest model
evaluated using 10-fold cross-validation with the
receiver operating characteristic (ROC) curve as the metric.
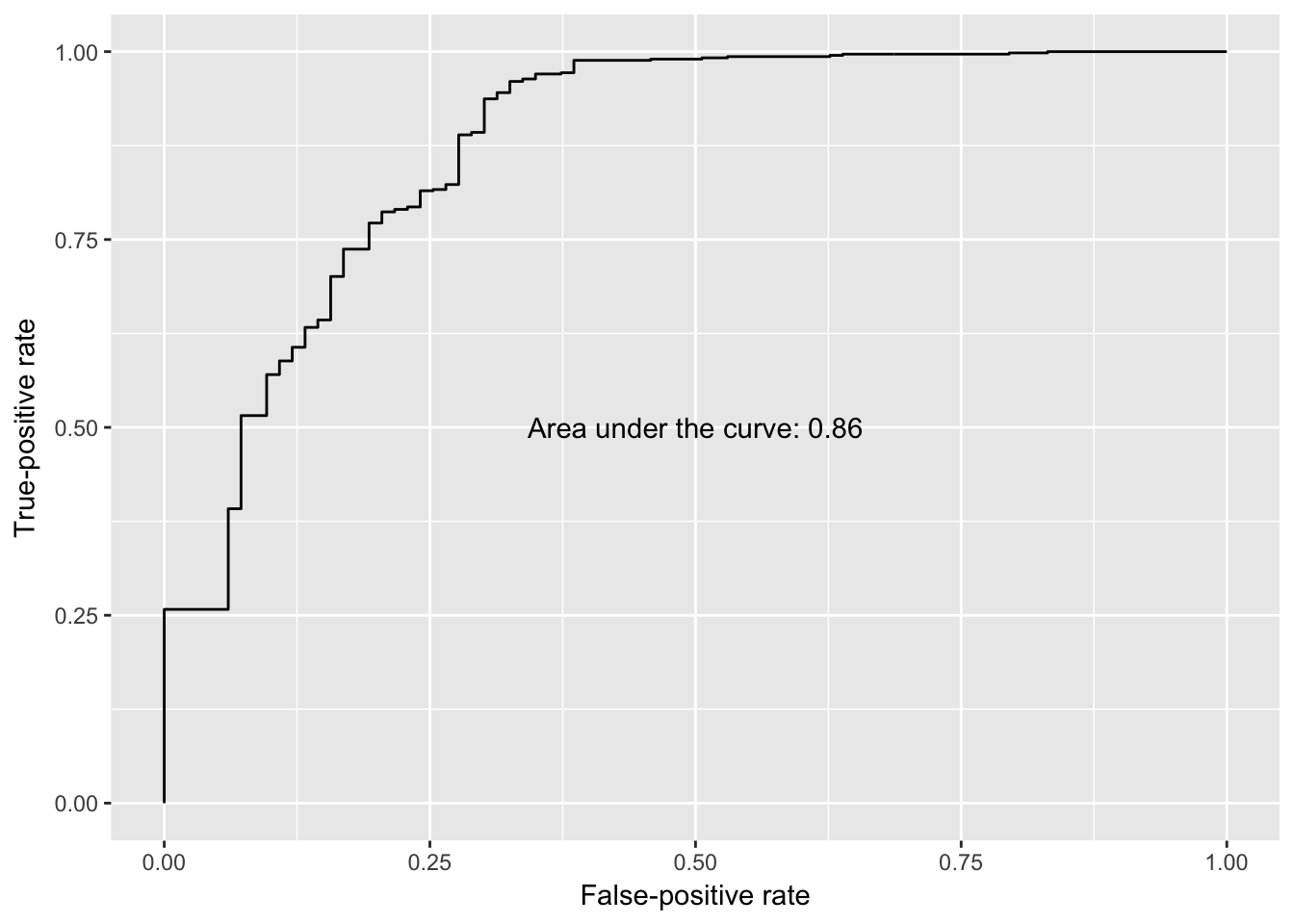
The ROC curve and area under the curve (AUC) for the model (when applied
to held-out test data from the training data set) are shown in the figure
below. An AUC of 0.86 is achieved with the initial set of six features.
Inclusion of date-time and bag-of-words features lead to over-fitting
Ten date-time features (such as ‘‘week of the year’’ and ‘‘day of the week’’)
are extracted from the timestamp column of the events.csv file.
When added to the model, the AUC actually decreases slightly,
indicating over-fitting. The AUC decreases even more when available
‘‘bag-of-words’’ data is included in the model.
Feature importance
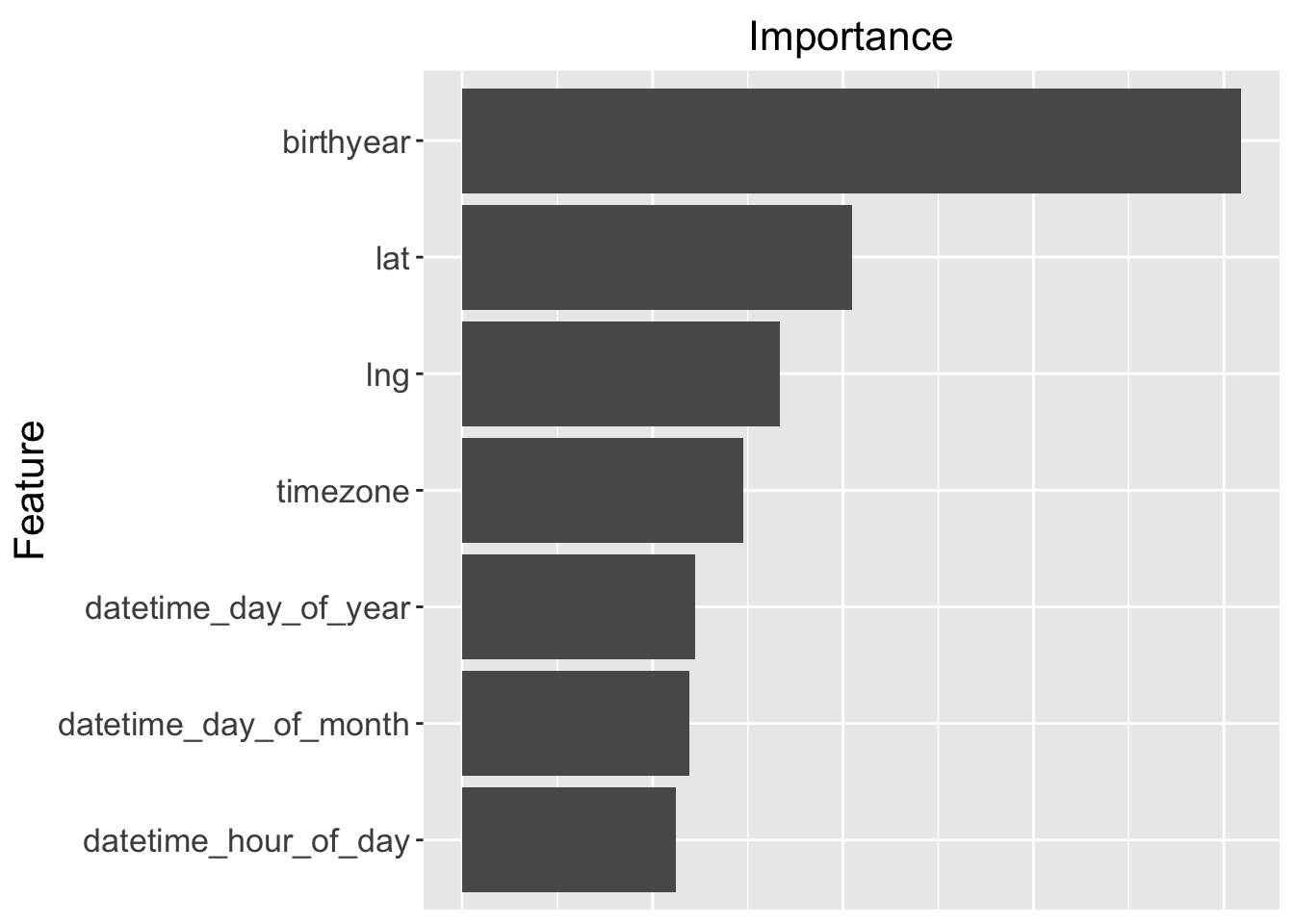
The varImp function from the caret package computes the
relative importance of each variable for objects produced by the train
method. A plot of the relative importance for the top seven variables
in the final random forest model is shown below.
Feedback welcome
If you have any feedback on the rwml-R project, please
leave a comment below or use the Tweet button.
As with any of my projects, feel free to fork the rwml-R repo
and submit a pull request if you wish to contribute.
For convenience, I’ve created a project page for rwml-R with
the generated HTML files from knitr, including a page with
all of the event-modeling examples from chapter 5.